
Big Data'ya Genel Bakış
Merak ettiğim ve ilgilenmeye çalıştığım bir konu olan Big Data
hakkında, sınıf arkadaşım Osman Taşdelen‘in ASELSAN stajı kapsamında yapmış olduğu Big Data'ya Genel Bakış adlı çalışmasından alıntılamak isterim.
Big Data
Diskte çok fazla yer kaplayan veri çağrışımı yapsa da aslında tam olarak böyle değildir. Big data sosyal medya paylaşımları, fotoğraf arşivlerimiz, sürekli kayıt aldığımız log dosyaları gibi farklı kaynaklardan elde ettiğimiz tüm bu verilerin anlamlı ve işlevlenebilir hale dönüştürülmüş biçimidir. Mesela; ilaç depolarında yüzbinlerce ilacın adını ve tam olarak nerde bulunduklarını, herhangi bir ilaca ulaşmak istediğimiz zaman yerini doğru bir şekilde bulabilmemizi sağlayan sistemlerin arkasında büyük veriler yatmaktadır.
Big Data Kullanım Alanları ile ilgili Örnekler;
1. Sosyal medya paylaşımları sayesinde hergün milyonlarca kilobayt veri elde edilmekte
2. Twitter’da günlük işlenen veri boyutu 7 terabyte’a yaklaşmakta ve günden güne artmaktadır.
3. Sağlık kuruluşları; hastalarına yönelik bireysel ve kişiselleştirilmiş sağlık hizmetleri sağlayabilmek için bireysel durumdaki verileri kendi sayısal ortamlarında depolamaktadırlar.
4. Arama motorları sayesinde milyonlarca sayfa arasında en doğru ve en hızlı veriye ulaşabilmemiz için yine aynı şekilde arka taraftaki büyük veriler ve bunların anlamlı hale getirilmeleri yatmaktadır.
Büyük ölçekli veri işlemek için oluşturulmuş birçok platform vardır. Bunlara Spark ,Storm Samza, Hadoop örnek verilebilir. Spark veriyi in-memory işlemek ve daha hızlı sonuçlar almak için tasarlarlanmıştır. Diğer platformlara göre bu avantajı vardır. Bu yüzden big data ile ilgili çalışmalar Spark frameworkü kullanılarak yapılmıştır.
Spark
Spark paralel veri işleme frameworküdür. Büyük ölçekli veri işlemek için oluşturulmuş platformdur. Spark, RDD(resilient distributed dataset) konsepti üzerine kurulu bir sistemdir. Bu da kabaca şu anlama gelir “veriler paralel işleniyor”. Spark veriyi teker teker işlemek yerine işlemleri yapan executerlara paylaştırıyor. Böylece RDD’ler üzerinde birden fazla işlem aynı anda paralel olarak yapılabiliyor. Spark’ın hızlı çalışmasının önemli sebeplerinden biri de RDD’lerdir. Çalışmada 503 bin satır verinin hılı bir şekilde işlenip gösterilmesi amaçlanmıştır. Yapılan çalışmada python dili ile beraber python’ın pyspark kütüphanesi kullanılmıştır. Bu kütüphane sayesinde veriler hızlı bir şekilde işlenebilmiştir.
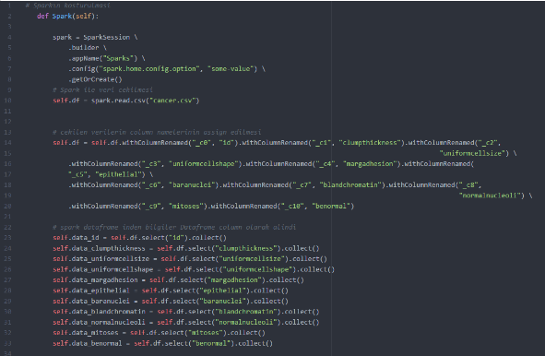
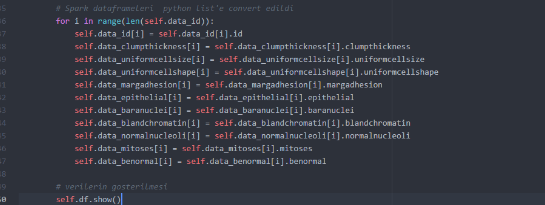

Projede Spark’ı koşturmaya başladığımızda kaç tane RDD bloğunun oluştuğunu, hafızanın ne kadar kullanıldığı bilgisini görebiliyoruz(via localhost:4041 yada localhost:4040)

Şekilde de görüldüğü gibi Spark veriyi teker teker işlemek yerine executerlara paylaştırıp veriyi öyle işliyor. Böylece verilerin paralel işlenmesini sağlıyor. Bu durum da verilerin çok daha kısa bir süre içerisinde veriyi işlememizi sağlıyor.
Yazar : Osman Taşdelen